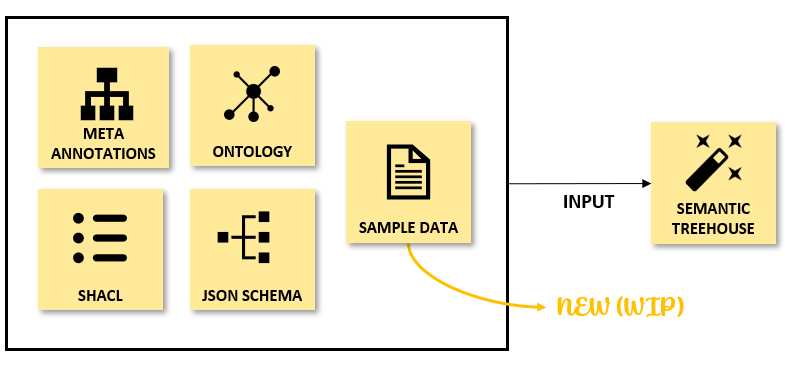
Vocabulary Support for Sample Data (CSV)


Semantic Treehouse is designed to maximize the reuse of common vocabularies (semantic standards) to ensure a shared understanding of the data. These vocabularies are assumed to be created through open standardization, meaning that they're created 'by the users, for the users'. Open standardization justifies what is essentially a top-down approach to interoperability: as soon as the standard is done, it is published in a central place and users are expected to comply by aligning their data to it.
However, there are various situations that would benefit from a more 'bottom-up' approach, i.e. where the information flow is reversed. Instead of Semantic Treehouse providing information on what vocabulary to use, users provide information on the usage of their data. This need arises in situation where, for example, there's only a loosely defined community where standards are not yet formed. Or when typical users don't have the resources or knowledge to work with semantic standards and make alignments. To overcome this hurdle, Semantic Treehouse has developed a new functionality that allows users to create an initial vocabulary based on their own sample data.